Datengenerator
Übersicht
Der Datengenerator in my8data ermöglicht das Erstellen von synthetischen Testdaten für Schulungs-, Demonstrations- und Testzwecke. Anstatt reale Messdaten verwenden zu müssen, können Sie mit dem Datengenerator gezielt Datensätze erzeugen, die bestimmte statistische Eigenschaften aufweisen.
Einsatzgebiete
| Einsatzgebiet | Beschreibung |
|---|---|
| Schulung und Training | Erstellen Sie Übungsdaten mit bekannten Eigenschaften, um die Interpretation von MFU, SPC und Prozessfähigkeit zu trainieren |
| Demonstration | Zeigen Sie Kunden oder Kollegen die Funktionen von my8data mit realistischen, aber anonymisierten Daten |
| Modultest | Überprüfen Sie die korrekte Funktion der Analysemodule mit Daten, deren erwartete Ergebnisse bekannt sind |
| Methodenvergleich | Vergleichen Sie verschiedene statistische Verfahren anhand identischer Datensätze |
| Sensitivitätsanalyse | Untersuchen Sie, wie sich Änderungen an Parametern (z. B. Streuung, Mittelwert) auf die Prozessfähigkeitskennwerte auswirken |
Info: Die generierten Daten werden mit einem Zufallsgenerator erzeugt und sind für statistische Analysen geeignet. Sie stellen keine realen Messwerte dar und sollten nicht für produktive Qualitätsentscheidungen verwendet werden.
Schnelleinstieg
So erzeugen Sie in wenigen Schritten einen Testdatensatz:
- Öffnen Sie den Datengenerator im Hauptmenü
- Wählen Sie den gewünschten Verteilungstyp (z. B. Normalverteilung)
- Legen Sie die Parameter fest (Mittelwert, Standardabweichung, Stichprobengröße)
- Klicken Sie auf Generieren
- Übernehmen Sie die erzeugten Daten direkt in ein Analysemodul oder exportieren Sie sie
Tipp: Um die Auswirkung verschiedener Szenarien zu testen, erzeugen Sie mehrere Datensätze mit unterschiedlichen Parametern. Beispielsweise können Sie einen fähigen Prozess (Cpk >= 1,67) und einen nicht fähigen Prozess (Cpk < 1,00) simulieren und die Ergebnisse vergleichen.
Parameter und Konfiguration
Verteilungstypen
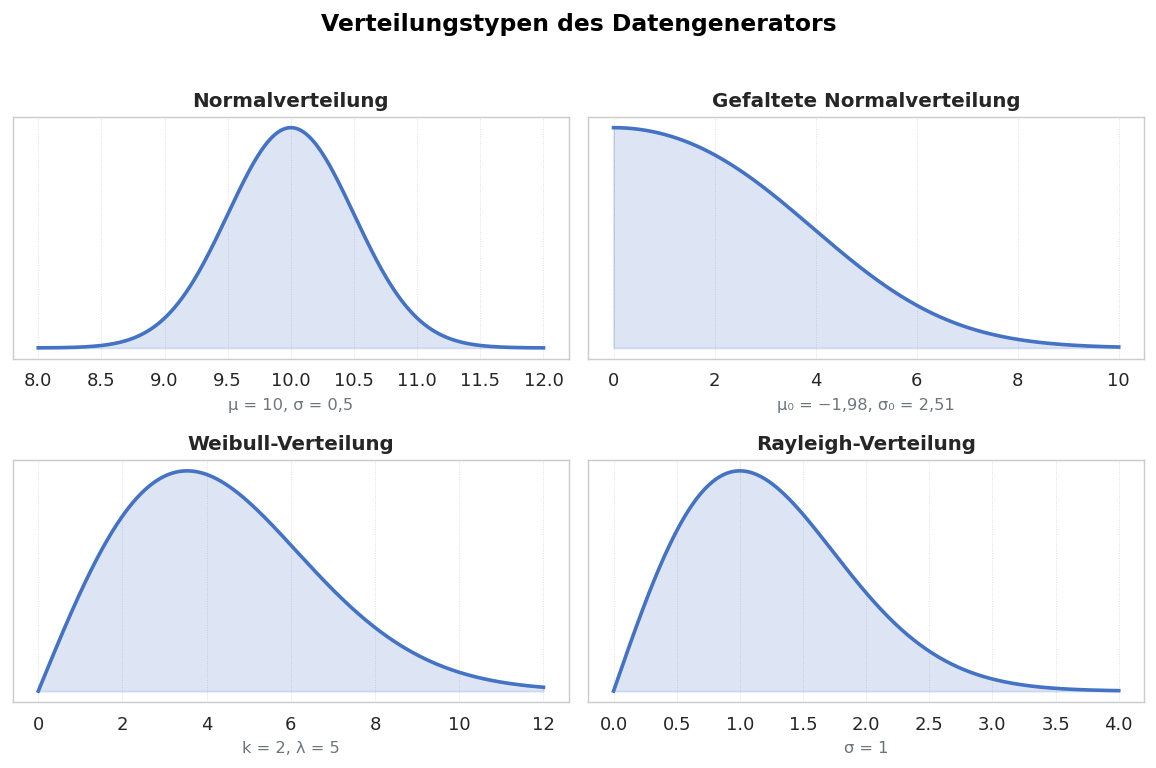
Der Datengenerator unterstützt verschiedene Verteilungstypen, um unterschiedliche Prozesssituationen zu simulieren:
| Verteilungstyp | Beschreibung | Typische Anwendung |
|---|---|---|
| Normalverteilung | Symmetrische Glockenform; am häufigsten in der Praxis | Standardfall für die meisten Fertigungsprozesse |
| Gleichverteilung | Alle Werte im Bereich gleich wahrscheinlich | Simulation eines Prozesses ohne klare zentrale Tendenz |
| Log-Normalverteilung | Rechtsschief; nur positive Werte | Rauheit, Partikelgrößen, Ausfallzeiten |
| Weibull-Verteilung | Flexible Form; kann schief oder symmetrisch sein | Lebensdaueranalysen, Zuverlässigkeit |
Konfigurierbare Parameter
Normalverteilung
| Parameter | Beschreibung | Beispielwert | Einfluss |
|---|---|---|---|
| Mittelwert (μ) | Zentrum der Verteilung | 10,00 | Verschiebt die gesamte Verteilung nach links oder rechts |
| Standardabweichung (σ) | Breite der Verteilung | 0,02 | Größere Werte erzeugen breitere Streuung |
| Stichprobengröße (n) | Anzahl der zu erzeugenden Werte | 100 | Mehr Werte erhöhen die statistische Aussagekraft |
Gleichverteilung
| Parameter | Beschreibung | Beispielwert |
|---|---|---|
| Minimum | Untere Grenze des Wertebereichs | 9,90 |
| Maximum | Obere Grenze des Wertebereichs | 10,10 |
| Stichprobengröße (n) | Anzahl der zu erzeugenden Werte | 100 |
Log-Normalverteilung
| Parameter | Beschreibung | Beispielwert |
|---|---|---|
| μ (log) | Mittelwert des logarithmierten Merkmals | 2,30 |
| σ (log) | Standardabweichung des logarithmierten Merkmals | 0,10 |
| Stichprobengröße (n) | Anzahl der zu erzeugenden Werte | 100 |
Weibull-Verteilung
| Parameter | Beschreibung | Beispielwert |
|---|---|---|
| Formparameter (k) | Bestimmt die Form der Verteilung | 3,5 |
| Skalenparameter (λ) | Charakteristische Lebensdauer / Skalierung | 10,00 |
| Stichprobengröße (n) | Anzahl der zu erzeugenden Werte | 100 |
Info: Bei der Weibull-Verteilung erzeugt ein Formparameter k < 1 eine fallende Verteilung (Frühausfälle), k = 1 entspricht einer Exponentialverteilung (zufällige Ausfälle), und k > 3 ergibt eine annähernd glockenförmige Verteilung (Ermüdungsausfälle).
Erweiterte Optionen
Zusätzlich zu den Grundparametern können Sie folgende erweiterte Einstellungen vornehmen:
| Option | Beschreibung | Standardwert |
|---|---|---|
| Startwert (Seed) | Startwert für den Zufallsgenerator; ermöglicht reproduzierbare Ergebnisse | Zufällig |
| Dezimalstellen | Anzahl der Nachkommastellen | 3 |
| Ausreißer hinzufügen | Fügt dem Datensatz gezielt Ausreißer hinzu | Deaktiviert |
| Anzahl Ausreißer | Wie viele Ausreißer eingefügt werden sollen | 0 |
| Ausreißer-Bereich | In welchem Bereich die Ausreißer liegen | ±4σ bis ±6σ |
Tipp: Verwenden Sie die Seed-Funktion, wenn Sie reproduzierbare Ergebnisse benötigen. Mit demselben Seed und denselben Parametern erhalten Sie immer den identischen Datensatz. Das ist besonders nützlich für Schulungen, bei denen alle Teilnehmer mit denselben Daten arbeiten sollen.
Praxisbeispiele
Beispiel 1: Fähiger Prozess simulieren
Ziel: Datensatz mit Cpk >= 1,67 erzeugen
| Parameter | Wert | Begründung |
|---|---|---|
| Verteilung | Normalverteilung | Standardfall |
| Mittelwert | 10,000 | Auf Sollwert zentriert |
| Standardabweichung | 0,010 | Geringe Streuung |
| Stichprobengröße | 100 | Ausreichend für Ppk-Berechnung |
| OSG | 10,050 | Toleranzbreite = 0,100 mm |
| USG | 9,950 |
Erwartetes Ergebnis: Cp ≈ Cpk ≈ 1,67 (Toleranzbreite 0,100 / 6 * 0,010 = 1,67)
Beispiel 2: Dezentrierter Prozess simulieren
Ziel: Datensatz mit Cp gut, aber Cpk schlecht
| Parameter | Wert | Begründung |
|---|---|---|
| Verteilung | Normalverteilung | Standardfall |
| Mittelwert | 10,025 | Absichtlich neben Sollwert |
| Standardabweichung | 0,010 | Gleiche Streuung wie Beispiel 1 |
| Stichprobengröße | 100 | |
| OSG | 10,050 | |
| USG | 9,950 |
Erwartetes Ergebnis: Cp ≈ 1,67, aber Cpk ≈ 0,83 (Prozess streut schmal, ist aber dezentriert)
Warnung: Synthetisch erzeugte Daten folgen exakt der gewählten Verteilung. Reale Prozessdaten weichen in der Praxis häufig von idealen Verteilungen ab. Die mit generierten Daten erzielten Ergebnisse sind daher oft "sauberer" als reale Analysen.